
Boa Noite Pessoal,
Semana passada começou excelente. Na virada do mês, lá estava eu curtindo a apresentação do DJ Paul Van Dyk no último live no Brasil (foi simplesmente fantástico). Foi ótimo para desestressar porém acabei tendo uma segunda-feira puxada e cansativa. Felizmente consegui tocar boa parte dos afazeres de SQL Server (pendências como sempre ainda estão presentes incluindo o post da semana passada). Finalmente consegui entregar o relatório final de um projeto de consultoria iniciado no ano passado. Durante a apresentação, eu relatei uma certa "anomalia" que havia identificado. Uma das tabelas mais utilizadas pelas aplicações possui nada mais que 17 índices. Isso foi sem dúvida algo que me impressionou, pois, em bancos OLTP normais não é nenhum um pouco comum encontrar essa quantidade de índices em um única tabela (se fosse um DW ainda ia). Imagine só uma operação de INSERT ter de escrever em mais 17 lugares além do próprio dado ? Sem dúvida um grande complicador em termos de desempenho. Na ocasião, um dos analista me perguntou se havia uma forma de identificar os índices que não estavam sendo utilizados. Eu não cheguei a levantá-los no relatório, mas não só a esse analista como a todos os demais que tenha essa dúvida, a resposta é sim. É possível levantar os índices que não estão sendo utilizados se o SQL Server for 2005 (ou superior). Não que no 2000 não desse, mas o processo era absurdamente mais trabalhoso. Vejamos como fazer isso.
— Muda o contexto para o TempDB
USE TempDB
— Cria uma tabela de Pessoas
CREATE TABLE Pessoas (CodigoPessoa INT NOT NULL,
Nome VARCHAR(50) NOT NULL,
CPF CHAR(11) NOT NULL,
Telefone CHAR(8) NOT NULL,
DDD CHAR(3) NOT NULL,
UF CHAR(2) NOT NULL,
DataNascimento DATE NOT NULL,
RowID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID())
— Insere 5 milhões de registros aleatórios
DECLARE @i INT = 1
WHILE @i <= 5000000
BEGIN
INSERT INTO Pessoas (
CodigoPessoa, Nome, CPF, Telefone,
DDD, UF, DataNascimento) VALUES (@i,
REPLICATE(CHAR(65 + (@i% 25)),40 + (@i % 10)),
REPLICATE(CAST((@i % 10) As CHAR(1)),11),
REPLICATE(CAST((@i % 5) As CHAR(1)),8),‘011’,‘SP’,
DATEADD(D,ABS(CHECKSUM(NEWID())) / 1000000,‘19700101’))
SET @i += 1
END
Agora que os registros estão devidamente cadastrados, o próximo passo é a criação de algumas constraints e índices.
— Cria as constraints
ALTER TABLE Pessoas ADD CONSTRAINT PK_Pessoas PRIMARY KEY (CodigoPessoa)
ALTER TABLE Pessoas ADD CONSTRAINT UQ_RowID UNIQUE (RowID)
— Cria os índices
CREATE INDEX IX_Nome ON Pessoas (Nome)
CREATE INDEX IX_RowID ON Pessoas (RowID)
CREATE INDEX IX_Telefone ON Pessoas (Telefone)
CREATE INDEX IX_UF ON Pessoas (UF)
CREATE INDEX IX_DDD ON Pessoas (DDD)
CREATE INDEX IX_DataNasc ON Pessoas (DataNascimento)
CREATE INDEX IX_DataNasc_UF ON Pessoas (DataNascimento, UF)
CREATE INDEX IX_UF_Telefone ON Pessoas (UF, Telefone)
CREATE INDEX IX_DDD_Telefone ON Pessoas (DDD, Telefone)
Visivelmente já existem alguns índices bem "inúteis". Antes de proferir as consultas para saber o que é útil ou não, é necessário cadastrar alguns registros a mais para que os resultados das consultas sejam os mesmos e que os registros aleatórios não interfiram.
— Insere mais cinco registros de pessoas
INSERT INTO Pessoas (CodigoPessoa, Nome, CPF, Telefone, DDD, UF, DataNascimento)
VALUES (5000001,‘Rildo’,‘70901232141’,‘99865455’,‘061’,‘DF’,‘19690314’)
INSERT INTO Pessoas (CodigoPessoa, Nome, CPF, Telefone, DDD, UF, DataNascimento)
VALUES (5000002,‘Gilvan’,‘25987341230’,‘32132234’,‘021’,‘RJ’,‘19680223’)
INSERT INTO Pessoas (CodigoPessoa, Nome, CPF, Telefone, DDD, UF, DataNascimento)
VALUES (5000003,‘Fábio’,‘45312967402’,‘84122932’,‘061’,‘DF’,‘19690314’)
INSERT INTO Pessoas (CodigoPessoa, Nome, CPF, Telefone, DDD, UF, DataNascimento)
VALUES (5000004,‘Renato’,‘56349087124’,‘84531278’,‘083’,‘PB’,‘19970221’)
INSERT INTO Pessoas (CodigoPessoa, Nome, CPF, Telefone, DDD, UF, DataNascimento)
VALUES (5000005,‘Genésio’,‘71234210943’,‘9738200’,‘061’,‘DF’,‘19650628’)
O SQL Server 2005 possui uma DMV própria para monitorar a utilização de índices chamada sys.dm_db_index_usage_stats. Essa view pode ser combinada com a view de catálogo sys.indexes para obter uma visão de utilização dos índices. O script abaixo (considerando que a tabela foi criada no TempDB), mostra essa visão:
— Muda o contexto do banco de dados
USE TEMPDB
— Consulta a utilização dos índices da tabela Pessoas
SELECT
DB_NAME(database_id) As Banco, OBJECT_NAME(I.object_id) As Tabela, I.Name As Indice,
U.User_Seeks As Pesquisas, U.User_Scans As Varreduras, U.User_Lookups As LookUps,
U.Last_User_Seek As UltimaPesquisa, U.Last_User_Scan As UltimaVarredura,
U.Last_User_LookUp As UltimoLookUp, U.Last_User_Update As UltimaAtualizacao
FROM
sys.indexes As I
LEFT OUTER JOIN sys.dm_db_index_usage_stats As U
ON I.object_id = U.object_id AND I.index_id = U.index_id
WHERE I.object_id = OBJECT_ID(‘Pessoas’)
O resultado é mostrado na tabela abaixo:
| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
Última Atualização |
| PK_Pessoas | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_UF | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_DataNasc | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
| IX_DDD_Telefone | 0 | 0 | 0 | NULL | NULL | NULL | 2010-02-08 13:47 |
A relação mostra todos os índices da tabela Pessoas. Nota-se que os dois primeiros registros não referem-se propriamente a índices, mas sim a constraints. Isso ocorre, porque constraints como primary keys e unique constraints necessitam criar um índice unique para garantir suas restrições de unicidade. Há maiores informações sobre elas em: Será que a opção IGNORE_DUP_KEY permite entradas duplicadas na chave primária e índices únicos ?.
As colunas de pesquisa, varreduras e lookups dão pistas sobre a utilização do índice. Em ordem de utilidade, na maioria das situações é preferível ter mais pesquisas, depois lookups e posteriormente varreduras. Índices que são utilizados somente para scans devem ser revistos, pois, podem significar índices mal projetados ou consultas mal elaboradas. As colunas subsequentes mostram quando o índice teve uma pesquisa, varredura, lookup ou atualização recente. As atualizações em um índice vão ocorrer sempre que houver um INSERT ou um DELETE, pois, a exclusão da linha necessariamente provoca variações no índice. No caso de operações de UPDATE, o índice será atualizado se a coluna que teve o UPDATE fizer parte do índice e alguns outros casos especiais.
Como nenhuma consulta foi realizada desde a criação dos índices, as colunas referentes a consultas (pesquisas, varreduras e lookups estão todas zeradas). A coluna de última atualização foi preenchida, pois, houve a inserção de cinco registros após a criação dos índices. Se essas inserções não tivessem ocorrido, a coluna última atualização não estaria preenchida.
Agora que existem registros "identificados", uma forma de verificar sua real necessidade dos índices sugeridos até então é a elaboração de algumas consultas para descobrir quais são realmente usados para recuperação dos dados. Para tornar os exemplos mais interessantes, vou incluir o plano de execução.
— Consulta 1
— Pesquisar quantos clientes existem em São Paulo
SELECT COUNT(*) FROM Pessoas
WHERE UF = ‘SP’

O resultado da consulta é alterado:
| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 0 | 0 | NULL | NULL | NULL |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
Como a consulta utilizou o índice para efetuar uma pesquisa (Seek), a coluna de pesquisas aumentou em uma unidade e a data da última pesquisa realizada com aquele índice foi atualizada deixando de ser nula.
— Consulta 2
— Pesquisar os clientes com DDD 061
SELECT * FROM Pessoas
WHERE DDD = ‘061’

| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 0 | 1 | NULL | NULL | 2010-02-08 15:32 |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 1 | 0 | 0 | 2010-02-08 15:32 | NULL | NULL |
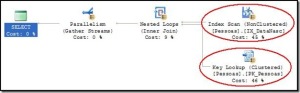
O índice IX_DDD_Telefone foi utilizado para pesquisa, mas como ele não possui todas as colunas necessárias, é preciso fazer um lookup para localizar os dados que estão no índice clustered. Essa operação é chamada de lookup e por isso, a chave primária foi utilizada para lookup.
— Consulta 3
— Pesquisar as pessoas com DDD 061
SELECT * FROM Pessoas
WHERE CONVERT(CHAR(10),DataNascimento,103) = ’23/02/1968′
| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 0 | 2 | NULL | NULL | 2010-02-08 15:32 |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 1 | 0 | NULL | 2010-02-08 15:55 | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 1 | 0 | 0 | 2010-02-08 15:32 | NULL | NULL |
O índice sobre a coluna data considera um tipo Date. A conversão para o tipo CHAR, "invalida" o índice para pesquisa. Nesse caso é necessário varrer toda a estrutura de índice para converter cada entrada para CHAR(10) e posteriormente fazer a pesquisa. Essa varredura (SCAN) faz com que o índice aumente a quantidade de varreduras de 0 para 1 e atualiza a data da última varredura. Como o índice não possui todas as colunas necessárias, foi necessário buscar os dados presentes no índice clustered aumentando a quantidade de lookups para 2.
— Consulta 4
— Pesquisar os 100 primeiros clientes que iniciam com a letra A
SELECT TOP 100 * FROM Pessoas
WHERE Nome LIKE ‘A%’

| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 1 | 2 | NULL | 2010-02-08 16:31 | 2010-02-08 15:32 |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 1 | 0 | NULL | 2010-02-08 15:55 | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 1 | 0 | 0 | 2010-02-08 15:32 | NULL | NULL |
Ao contrário do que poderia parecer, o índice sobre a coluna Nome sequer foi utilizado (possivelmente por conta da cardinalidade). Como a tabela é clusterizada, ou seja, possui um índice clustered, ela foi simplesmente varrida para que os nome fossem comparados aumentando para 1 a quantidade de scans na chave primária.
— Consulta 5
— Pesquisar um RowID específico
SELECT * FROM Pessoas
WHERE RowID = ‘2E50F357-A814-DF11-BDFB-18A9056DE331’

| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 1 | 3 | NULL | 2010-02-08 16:31 | 2010-02-08 15:32 |
| UQ_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_RowID | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 1 | 0 | NULL | 2010-02-08 15:55 | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 1 | 0 | 0 | 2010-02-08 15:32 | NULL | NULL |
Esse é um detalhe interessante. O índice UQ_RowID é um índice derivado da constraint UQ_RowID e é o mesmo que o índice IX_RowID, mas mesmo assim, o SQL Server optou por escolher o IX_RowID. Eles são idênticos e tanto faz, pois, o resultado é o mesmo. Entretanto, há um duplo overhead, pois, os dois índices precisam ser mantidos. A exclusão do índice IX_RowID permitirá que o índice UQ_RowID seja utilizado.
— Elimina o índice IX_RowID
DROP INDEX Pessoas.IX_RowID
— Consulta 6
— Pesquisar um RowID específico
SELECT * FROM Pessoas
WHERE RowID = ‘2E50F357-A814-DF11-BDFB-18A9056DE331’

| Índice | Pesquisas | Varreduras | Lookups | Ultima Pesquisa |
Última Varredura |
Último LookUp |
| PK_Pessoas | 0 | 1 | 3 | NULL | 2010-02-08 16:31 | 2010-02-08 15:32 |
| UQ_RowID | 1 | 0 | 0 | 2010-02-08 17:00 | NULL | NULL |
| IX_Nome | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF | 1 | 0 | 0 | 2010-02-08 15:03 | NULL | NULL |
| IX_DDD | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DataNasc | 0 | 1 | 0 | NULL | 2010-02-08 15:55 | NULL |
| IX_DataNasc_UF | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_UF_Telefone | 0 | 0 | 0 | NULL | NULL | NULL |
| IX_DDD_Telefone | 1 | 0 | 0 | 2010-02-08 15:32 | NULL | NULL |
Com o índice IX_RowID eliminado, o índice UQ_RowID foi utilizado incorrendo no mesmos custos do índice IX_RowID.
A consulta utilizada mostra como verificar a utilização de cada índice. Um pequeno ajuste mostrará os índices completamente não utilizados permitindo uma eventual revisão de sua real necessidade.
— Muda o contexto do banco de dados
USE TEMPDB
;WITH IndicesNaoUtilizados As (
SELECT
DB_NAME(database_id) As Banco, OBJECT_NAME(I.object_id) As Tabela, I.Name As Indice,
U.User_Seeks As Pesquisas, U.User_Scans As Varreduras, U.User_Lookups As LookUps,
U.Last_User_Seek As UltimaPesquisa, U.Last_User_Scan As UltimaVarredura,
U.Last_User_LookUp As UltimoLookUp, U.Last_User_Update As UltimaAtualizacao
FROM
sys.indexes As I
LEFT OUTER JOIN sys.dm_db_index_usage_stats As U
ON I.object_id = U.object_id AND I.index_id = U.index_id
WHERE database_id = DB_ID())
SELECT
Banco, Tabela, Indice, Pesquisas, Varreduras, LookUps,
UltimaPesquisa, UltimaVarredura, UltimoLookUp
FROM IndicesNaoUtilizados
WHERE
(Pesquisas + Varreduras + LookUps) = 0
Um índice sempre terá a última data de atualização preenchida quando ocorrerem inserts e deletes (e updates em alguns casos). A utilidade de um índice significa que ele é capaz de auxiliar nas consultas recuperando os dados mais rapidamente. Se esse índice não é utilizado para nenhuma operação que envolve recuperação como pesquisa (Seek), varredura (Scan) ou o Lookup ele é um sério candidato a ser eliminado.
Fragilidades do método
Embora essa seja uma abordagem interessante para detectar alguns índices inúteis, ela em por si só não é tão eficaz se não forem observados alguns outros pontos de análise.
Acuracidade dos dados das DMVs
Por padrão, as DMVs iniciam a coleta de dados no momento em que o SQL Server é iniciado. Isso significa que mesmo que os índices existam, se o SQL Server for reiniciado, automaticamente todos os contadores serão zerados. Se um índice for criado e muito utilizado, mas após reiniciar o SQL Server ele não for mais usado, a DMV poderá apontar como zero a soma das pesquisas, varreduras e lookups e isso pode levar a falsas interpretações.
Conhecimento das rotinas de negócio
Muitas vezes um índice pode ser aparentemente desprezado por passar longos períodos de tempo sem utilização. Entretanto é possível que rotinas batch ou ainda relatórios mensais, trimestrais, etc tenham necessidade de utilizá-lo. Sem conhecer essas rotinas, algum índice pode ser excluído indevidamente e provocar problemas de desempenho.
Índices utilizados para restrição
Nem sempre o papel de um índice está relacionado à recuperação rápida de dados. Primary Keys e Unique Constraints dependem de índices, pois, é o mecanismo que elas possuem para garantir a unicidade. Especialmente no caso das Unique Constraints, pode acontecer dos índices serem criados para impedir registros duplicados e talvez ele nunca sejam realmente utilizados para pesquisa. Essa característica é comum também para índices unique criados sem a associação a uma constraint.
Dependência do banco de dados
A consulta que eu elaborei depende da DMV sys.dm_db_index_usage_stats e da view sys.indexes. Por ser uma DMV, a sys.dm_db_index_usage_stats retorna os dados de toda a instância independente do banco executado (desde que haja as devidas permissões para tal). No caso da sys.indexes, é necessário estar logado no banco de dados desejados para que os dados dela possam ser retornados corretamente. Pode-se utilizar somente a sys.dm_db_index_usage_stats, mas não será possível obter alguns dados como o nome do índice ou ainda as colunas participantes (sys.index_columns).
E Por que se preocupar com índices não utilizados ?
Se analisarmos as estruturas de índices, elas representam uma certa redundância. O índice é uma "cópia" de parte dos dados em uma organização própria para facilitar a recuperação. O simples fato de ser uma "cópia" impõe duas desvantagens naturais. A primeira é que será necessário espaço adicional para armazenar essas "cópias parciais". A segunda é que por serem "cópias" utilizadas para pesquisas, elas devem ser mantidas de forma síncrona com os dados reais, ou seja, a gravação de um registro deve necessariamente atualizar todos os índices. Isso significa um custo de I/O adicional. Isso significa que na melhor das hipóteses um índice pode auxiliar a recuperação de dados (não é 100% garantido), mas sempre irá prejudicar a gravação de dados (isso é 100% garantido) e por isso devem ser criteriosamente escolhidos. Eliminar os índices desnecessários já é um ponto positivo na criação de uma proposta de reindexação.
[ ]s,
Gustavo

Muito bom!Parabéns Gustavo.
Gustavo caramba vi que vc manja muito. poderia de dar algumas dicas de onde posso conseguir material de estudo sql.
valeu
Oi Leandro,
O meu blog é um bom caminho hehehehe. Há varios blogs e sites interessantes, mas eu não dispensaria bons livros. Dê uma olhada no programa MSDN Experience.
Abs,
Gustavo, na query reparei que você incluiu a quantidade de lookups que o “select” executa no retorno das informações. Caso esse lookup seja alto, existe a necessidade de rever as querys montadas que utilizam o indice?
[]’s
Oi Patrício,
Se um índice é usado (mesmo pra lookup) houve um acesso a dados e por isso inclui na minha pesquisa. Agora especificamente sobre lookups é difícil afirmar algo sobre eles apenas com base na quantidade. É possível que haja muitos lookups, mas que nem por isso seja algo dispendioso ou que tenha de ser revisto. Na verdade o lookup é justamente o grande papel do índice, ou seja, prover uma forma mais rápida de chegar ao dado. O que posso indicar é que muito lookups são um incentivo a índices com a cláusula INCLUDE, mas ainda assim temos de ver.
Rever as consultas antes de rever o índice é algo sempre recomendável. Muitas vezes os índices estão corretos, mas as consultas mal escritas podem não usufruir deles da melhor forma.
[ ]s,
Gustavo